
2 Probability
E.F. Redish
By the end of this chapter, you should be able to…
- Defining probability in terms of an infinite number of trials.
- Calculating the mean and standard deviation for results with different amounts of probability.
- Defining microstate.
- Defining macrostate.
Introducing Probability
Probability is one of those words for which we all have an intuition, but which is surprisingly hard to define. For example, try, more concretely, to define what it means for a coin to have an “equal probability” of coming up heads or tails—but without using words in your definition that are synonymous to “probability” (such as “chance” and “likely”). It’s really hard to do! In fact, entire branches of philosophy have been devoted to the question of how to define what is meant by “equal probability”. So if you find yourself thinking hard about the probabilities we encounter, you are in good company!
The key idea in probability is lack of control. When we flip a coin, it’s extremely hard to control which way the coin will come down. The result is very sensitive to the starting conditions you give it at a level of sensitivity greater than you can control. Which, of course, is the point of flipping a coin.
One definition of “equal probability” might look something like this:
As the number of tosses of a fair coin approaches infinity, the number of times that the coin will land heads and the number of
times that the coin will land tails approach the same value.
Is that a useful definition? Maybe, but it doesn’t seem to capture everything that we intuitively know to be true. We’d like to know what the chances are that the coin will land on “heads” when we toss it just once, without having to toss it an infinite number of times. And we all have the feeling that the answer is obvious – it’s ½! – even if we have a hard time expressing it rigorously.
How would we know if it’s fair?
Of course determining whether a coin is “fair” or not would require testing it an infinite number of times. And in the real world we expect that no real coin would be perfectly fair. It might be a tiny bit unbalanced so that it consistently, over many many flips, comes out 0.1% more heads than tails. Would we accept that as a “fair” coin?
One of the interesting questions of probability is “how do you know” that a coin is fair, for example? Or better: how well do you know that a coin “appears to be fair”? This subject carries us beyond the scope of this class into the realm of Bayesian Statistics . We won’t discuss that here, though we will note that Bayesian analyses play a large role in the modern approach to medical diagnosis and both medical students and biological researchers will eventually have to master this subject!
A simple model for thinking about probabilities: a fair coin
Rather, we will make a simplified model that we can analyze in detail mathematically. We will assume that we have a (mathematically) fair coin — one that if it we flipped it an infinite number of times would come up an equal number of times heads and tales.
Now we can get back to our story. Let’s see if we can make some interesting observations about probabilities by relying on just our intuitions. Suppose, for example, that I toss a (mathematically) fair coin ten times. How many times will it come up “heads”? The correct answer is: who knows! In ten flips, the coin may land on heads seven times, and it may land on heads only twice. We can’t predict for sure. But what we do know is that if it is a fair coin it is more likely that it will land on heads 5 times than it is that it will land on heads all 10 times.
But why do we feel that is the case? Why is the result of 5 heads and 5 tails more likely than the result of 10 heads and 0 tails? If each toss is equally likely to give heads as it is to give tails, why is the 5/5 result more likely than the 10/0 result? The answer is that there are many more ways for us to arrive at the 5/5 result than there are ways for us to arrive at the 10/0 result. In fact, there is precisely ONE way to arrive at the 10/0 result. Note that in stating “5/5” we are assuming that we don’t care in which order the heads and tails appear — we only care about the total number.
If we only care about the totals: microstates and macrostates
If we only care about the totals there is only ONE way in which you would arrive at the result that the series of tosses produced 10 heads: HHHHHHHHHH. You have a 50% chance the first flip will be a head, a 50% change the second will be a head, and so on. Therefore the probability of 10 heads is 1/210 or 1 in 1024.
On the other hand, here are just a few of the 252 ways of arriving at the 5/5 result: HHHHHTTTTT, HTHTHTHTHT, TTTTTHHHHH, HTTHHTTHTH. Each of these particular strings also only has the probability of 1 in 1024 to come up, since there is a 50-50 chance of a head or a tail on each flip. But since there are 252 ways of arriving at 5/5 the chance of finding 5/5 (in any order) is 252/1024 — much great than finding 10/0 and in fact greater than finding any other specific mix of heads and tails.
Another way of expressing the probabilistic intuition we have been describing is to say that a system is much more likely to be in a state that is consistent with many “arrangements” of the elements comprising the state than it is to be in a state consistent with just a few “arrangements” of the elements comprising the state. An “arrangement” in the coin toss discussion corresponds to a particular ten toss result, say, HTTHTTHHHT. The 10/0 result is consistent with only one such arrangement, while the 5/5 result is consistent with 252 such arrangements.
The difference between a specific string of heads and tails and the total count (in any order) is a model of a very important distinction we use in our development of the 2nd Law of Thermodynamics. The specific string, where every flip is identified, is called a . The softer condition — where we only specify the total number of heads and tails that result — is called a . In our mathematical fair coin model, what “fair” means is that every microstate has the same probability of appearing.
What happens as the number of tosses increases from 10 to, say, 1000? As you might guess, it becomes even more likely to obtain a result near 500/500 than it is to obtain a result near 1000/0. In the jargon of statistics, the probability distribution gets “sharper.”
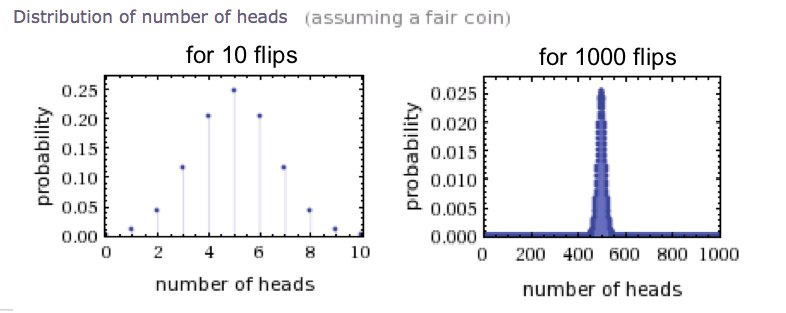
In chemical and biological systems we often deal with HUGE numbers of particles, often on the scale of moles (one mole of molecules contains more than 1023 particles!) so one can imagine what the probability distribution looks like in such cases. It is incredibly sharp. The only macrostate that we ever see is the most probable one. Regularities emerge from the probability that are (as long as we are talking about many particles) as strong as laws we consider to be “absolute” instead of “probabilistic”.
Homework
Microstates of macrostates.
The specific condition of each individual element of the system. If these are individual atoms, then we might speak of their positions, velocities, or other properties. In the case of multiple dice, we might speak of the result of each individual dice thrown.
A "overall" picture of a system. This can be defined however the observer wishes. It could include such overall properties as volume, temperature, density, total energy, or more "contrived" properties such as the number of 1's that result from rolling a handful of dice.
